Program Schedule
Timetable:
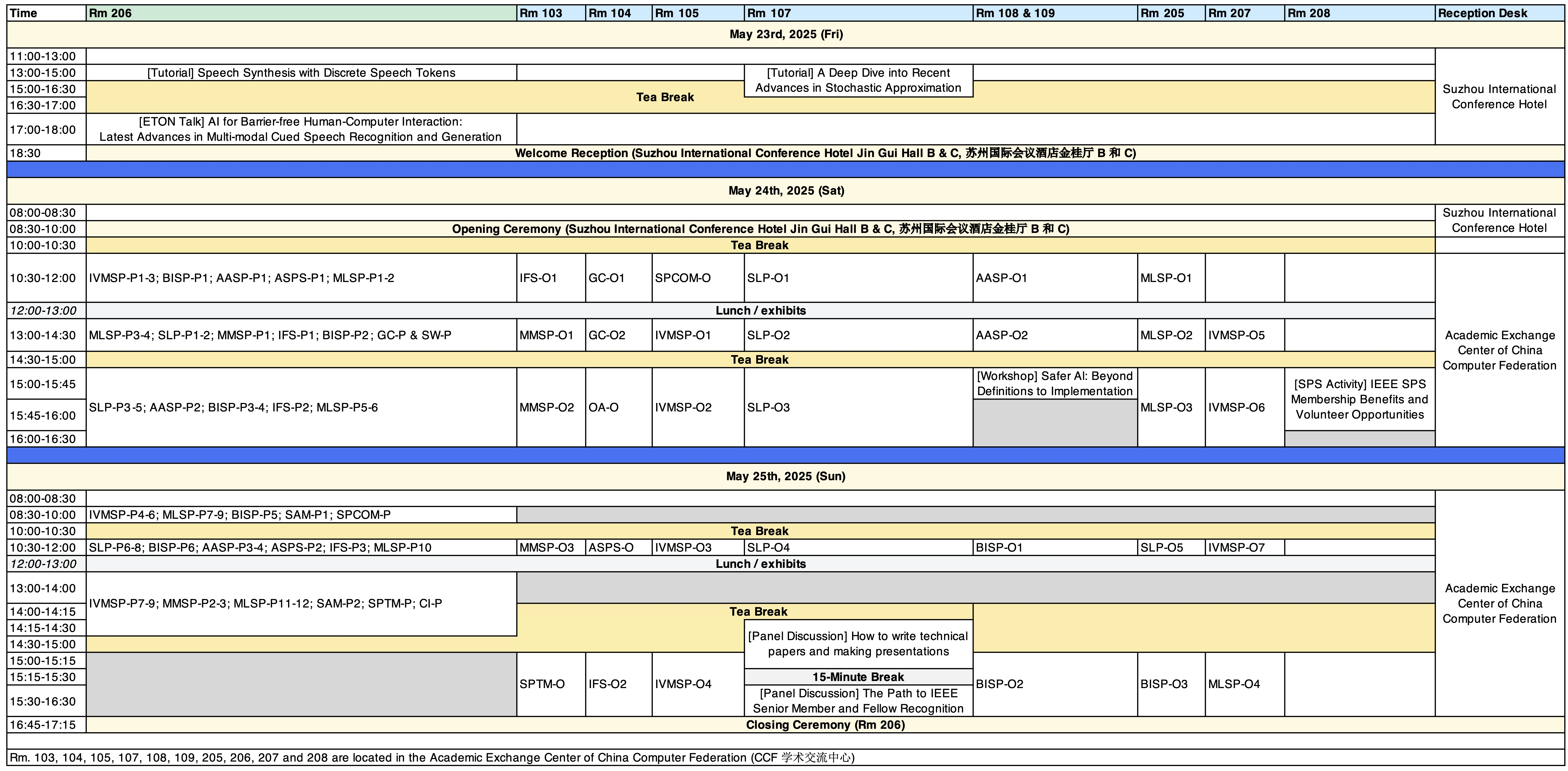
The timetable can also be downloaded via this link: Timetable.pdf
The programme book can be downloaded via this link: Programme_Book.pdf
Introduction to the Tutorial and ETON Talk on May 23:
Tutorial 1:
TUT-1: Speech Synthesis with Discrete Speech Tokens
Room: Rm. 206
Type: Tutorial
May 23rd 13:00-15:00
Presenter: Kai Yu (Shanghai Jiao Tong University)*; Shujie Liu (Microsoft Research Asia); Xie Chen (Shanghai
Jiaotong University); Yiwei Guo (Shanghai Jiao Tong University)
Chair: TBA
Tutorial 2:
TUT-2: A Deep Dive into Recent Advances in Stochastic Approximation
Room: Rm. 107
Type: Tutorial
May 23rd 13:00-16:30
Presenter: Gersende Fort (CNRS); Eric Moulines (Ecole Polytechnique); Hoi-To Wai (Chinese University of Hong
Kong)*
Chair: TBA
ETON Talk:
ETON: AI for Barrier-free Human-Computer Interaction: Latest Advances in Multi-modal Cued Speech Recognition
and Generation
Room: Rm. 206
Type: Tutorial
May 23rd 17:00-18:00
Presenter: Li Liu (Hong Kong University of Science and Technology, Guangzhou)
Chair: TBA
Dr. Li Liu Assistant Professor at Hong Kong University of Science and Technology
Abstract: In today’s world, where AI technology is rapidly evolving, ensuring that everyone can communicate effectively is more important than ever. This is especially true for the deaf and hard-of-hearing community. Our research focuses on enhancing communication through the development of Automatic Cued Speech (CS) systems. In this talk, I will first introduce the effective yet simple CS system, and then discuss our innovative cross-modal mutual-learning framework that uses a low-rank Transformer for improved CS recognition. This system significantly enhances language integration across different modalities through modality-independent codebook representations. Additionally, I will highlight our thought-chain prompt-based framework for CS video generation, which leverages large language models to accurately and diversely link textual descriptions with CS gesture features. Our efforts have led to the creation of the first large-scale multilingual Chinese CS video dataset, setting new standards in CS recognition and generation across languages like Chinese, French, and English. Besides, I will introduce personalized speech generation and face image synthesis, aligned with speech and visual cues. This research is paving the way for more inclusive and effective Human-Computer Interaction, ensuring that technology can truly be accessible to everyone.
Biography: Dr. Li Liu is an assistant professor at AI Thrust, Information Hub, Hong Kong University of Science and Technology (Guangzhou). She obtained her Ph.D. degree from Gipsa-lab, University Grenoble Alpes, France. Her main research interests include multi-modal audio-visual speech processing, AI robustness and AI for healthcare. As the first author or corresponding author, she has published about 50 papers in top journals and conferences in related fields, including IEEE TPAMI, IEEE TMM, IEEE TMI, NeurIPS, ICCV, ACM MM and ICASSP etc. She was Local Chair (China site) ICASSP 2022 and Area Chair of ICASSP 2024 and 2025. In 2017, she won the French Sephora Berribi Award for Female Scientists in Mathematics and Computer Science. She obtained several scientific research projects, including the NSFC General Project and Guangdong Provincial Natural Science Foundation-General Project etc. Her paper was awarded the Best Student Paper Nomination Award at the International Conference on Social Robotics 2024, and four papers were selected as the Shenzhen Excellent Science and Technology Academic Papers in 2022 and 2023.